1. INTRODUCTION
The number of visitors to internet has been expanded intensely and the quantity of content has grown exponentially. Thus, the challenge is now significantly higher as to how you may conduct searching and/or recognizing the data. Several data categories in web applications are available such as texts, audios, videocassettes, charts, and diagrams. The most common and important type of data media that have been used by users on the internet is text. Texts are mainly used for scientific purposes such as communication, conversation, and exchange ideas, facts, and opinions. Hence, it is used for classification, handling, and unifying huge amount of information of different applications such as clarifying bulletins, health coding, web surfing, and information retrieval. Information contents in text classification are characterized depending on each document meaning. T hus, automatic machine learning techniques as replacements for a rule-based approach are used for classification (Mohammed et al., 2018; Karthik et al., 2016).
A wide range of machine learning classifiers has been used to classify documents such as C4.5, K-Nearest Neighbors (KNN), and Support Vector Machine (SVM) are examples of machine learning classifiers that have been used to classify documents (Sharma et al., 2016). Nonetheless, some imperative preprocessing steps are needed to be conducted on the data sets before classification task to ensure the performance and accuracy of classifiers are achieved. These imperative steps are tokenizing, removing stop words, and stemming (Bahassine et al., 2014).
Stemming is one of the above steps that can be employed on the text document for obtaining the root of word or the Stem. Usually, it is used for word standardization through taking away the affixes of the words. It is supportive in numerous applications such as information retrieval, compression of texts, computational linguistics, and categorization of texts (Duwairi et al., 2007; Esmaili et al., 2013).
Several scientists have applied stemmers on various languages such as English, Dutch, Slavic, and others. The efficiency of using stemmers appears more on some languages that have extra complex morphology than others for instance, the usefulness of using stemmers in Slovene language is more visible than English or Dutch, and this is because Slovene is more complex than English and Dutch (Tanja Gaust, 2002). The Kurdish language also has complex morphology, and in addition, it has huge inflectional and derivational affixes. Hence, a Kurdish stemmer is very significant to stem Kurdish documents. Nonetheless, such challenges are still considered to be at their early days (Saeed et al., 2018).
In this paper, a new stemming approach for Kurdish Sorani texts is suggested for obtaining the root of the words. Approximately 40–45 million people speak the Kurdish language in four states: Turkey, Iran, Iraq, and Syria. In general, the Kurdish language is part of Indo-European family, and specifically, it is part of the Iranian group. The Kurdish language has several dialects, but the most common types are Sorani and Kurmanji. The Sorani dialect is used only in Iraq and Iran, whereas the Kurmanji dialect used in all the four parts of Kurdistan. The Kurdish language has two different official scripts. The Sorani dialect uses an Arabic script in which the writing style is from right-to-left, whereas the Kurmanji dialect uses Latin script and writing style is from left-to-right. The dataset in this research was collected from different online websites that were written in Arabic script with Kurdish Unicode Fonts (Rashid et al., 2017; Salavati et al., 2013). The dataset can be obtained from the following link https://archive.ics.uci.edu/ml/datasets/ KDC-4007+dataset+Collection. With the availability of this data, a problem of not recognizing Kurdish texts with several local fonts which are available on the internet will be avoided by users or readers when uploading data or downloading data.
In this research work, SVM and C4.5 are implemented on this stemmer through utilizing (Rashid et al., 2017).
2. RELATED WORK
There are numerous techniques that have been developed to produce stemmers for different languages such as English, Arabic, and Persian for enhancing the accuracy in text classification; nonetheless, the number of stemmers in Kurdish are few and the research works on this area are few.
The KNN, Naïve Bayesian (NB), J48, and sequential minimal optimization (SMO) classifiers were applied for evaluating both the Light and Khoja stemmers on Arabic texts. Features are reduced through using normalization process. The digits, formatted tags, special marks, punctuation marks, and Latin words are removed. Their experimental results demonstrated that the light stemmer outperformed the Khoja stemmer when 10-fold cross validation technique was used. The evaluation process is performed on the classifiers through using the weighted average of F-measure, precision, and recall. In SMO, all instances are classified correctly when the light stemmer was applied (Khalid et al., 2016; Mamoun and Mahmoud, 2016).
In an evaluation research work, a novel method was applied for evaluating a classifier using Information Gain (IG) as a feature selection technique. Both Bayesian networks (BN) and multinomial NB (MNB) were applied as classifiers. Their experiential results were assessed through three datasets for training and testing the proposed method. The datasets were Reuters-REO, Review Polarity, and Reuters-REI. The proposed method outperformed on six classifiers (BN, KNN, MNB, SVM, NV, and decision tree) (Rahman and Usman, 2016).
A new research work for assessing information retrieval on Kurdish Sorani texts through Pewans dataset was proposed. The Pewan is the first typical test collection for Sorani language. It was collected from both Peyamner and VOA as two online news agencies. The dataset size was 1 KB and collected between 2003 and 2012 (18420 articles from VOA and 96920 articles from Peyamner). In this research study, a list of stop words was created that involved 282 extremely regular words and the N-gram was applied for accumulating 30 lists of affixes. The light stemmer was constructed for assessing the effectiveness of information retrieval on the documents. The experiment indicated that the quality of information retrieval system can be improved through applying the stemmer and the performance of information retrieval is enhanced in Sorani texts (Esmaili et al., 2013).
A stemmer for Kurdish Sorani texts was developed for reducing discrepancies of words to roots. Their experimental results showed that the effectiveness of information retrieval was increased and the dimensionality of feature vectors in documents was decreased when the stemmer was used. It was concluded that the processes that were applied to Kurdish Sorani texts could be revised and applied in Kurdish Kurmanji too for greater efficiency (Saeed et al. 2018; Salavati et al., 2013).
3. PROPOSED APPROACH
In this section, an innovative approach is used for stemming Kurdish text classification. There are some comprehensive steps in classification before conducting it. These steps are raw data collection, pre-processing on data, data representation, and finally, classification (Esmaili et al., 2013) as shown in Figure 1.
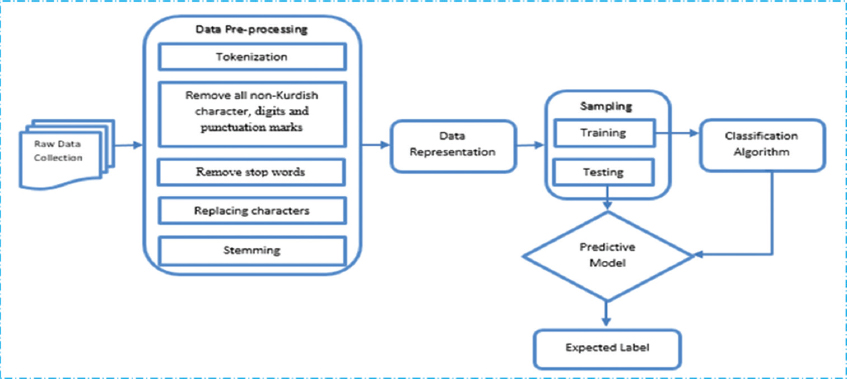
Figure 1. Proposed method
3.1. Dataset Collection
The dataset in this research work is collected from different websites. The data contain 4007 text files that are categorized manually for eight different classes; they are economy, education, style, sport, art, health, religion, and social. Each class is equally distributed to have 500 class documents (Rashid et al., 2017).
3.2. Data Pre-processing
The preprocessing steps are applied for reducing the noise of data and number of the features. These preprocessing steps are as follows (Alajmi et al., 2012; Alami et al., 2016):
-
Tokenization, this is applied to break up the sentences into words through removing spaces.
-
Eliminate all non-Kurdish characters, digits, punctuation marks, and numbers.
-
Eliminate stop words and useless words. This research works prepares a list of stop words. This list contains 240 stop words (Rashid et al., 2017).
-
Replacing characters such as:
“
 ”+ space with “
”+ space with “ ”
”-
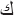 with
with 
-
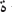 with
with 
-
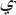 with
with 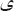
-
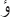 with
with 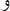
-
-
Stemming, this is the most significant part of this research work as it has greater impact on the classification of Kurdish text. The stemming approach can be divided into two common approaches. These are called a rule-based approach and a statistical approach. In the rule-based approach usually, a set of rules are applied for removing suffixes of each word that terminated with a set of suffixes. The algorithm of Lovins is the initial implementation, which contains 35 transformation rules, plus 294 endings with 29 circumstances. In addition, there is Porter’s stemmer that contains 60 rules collected in five steps as base rules for obtaining the root of words. On the other hand, there are some statistical methods, which can use a dictionary for determining the root, and for instance, there is Yass stemmer through which distance measure is used for identifying the clustering-based approach for distinguishing the class. On the other hand, the Yass stemmer is an example of statistical method via which a dictionary is used for determining the root. The Yass stemmer is applied on the French and Bengali for enhancing the information retrieval performance. Yass stemmer is evaluated against Lovin and Porter stemmers; nonetheless, it requests an inclusive statistical linguistic resources and tools for implementation (Salavati et al., 2013). In this research work, a list of prefixes and suffixes are used for determining the stem of the word as shown in Table 1. The following points are the main features of the proposed approached:-
Table 1. List of prefixes and affixes

-
The approach consists of nine levels that start with a feature or token and ends with a leaf or a stem.
-
The token can hold three prefixes and six suffixes. Hence, three levels are assigned for removing three prefixes and six levels for removing six suffixes.
-
If the token starts with one of prefixes and the length of token is >3, then the prefixes are removed and the process is repeated 3 times, for instance, in token (
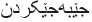 ), in the first process, (
), in the first process, (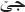 ) is removed in the first level, then (
) is removed in the first level, then (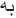 ) is removed in the second level, after that another (
) is removed in the second level, after that another (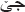 ) is removed in the third level, and (
) is removed in the third level, and (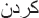 ) is remained.
) is remained. -
The rest of the levels (4 till 9) are used for removing the suffixes of the token, and if the token is ended with one of the suffixes and the length of the token is >3, then the suffixes are removed as the first level and the process is repeated till the last level.
-
The last level is leaves (stems), the best stem is selected by evaluating all stems to get the smallest one, and the length of stem must be >2 as shown in Figure 2.
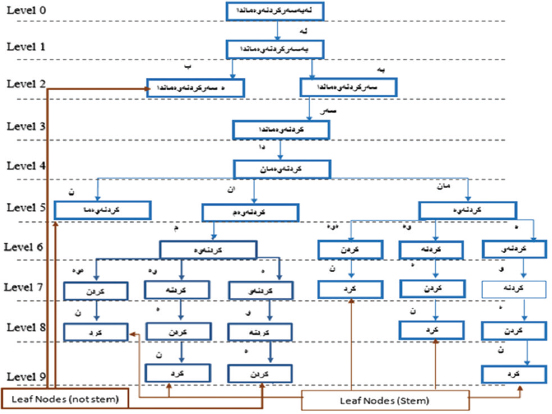
Figure 2. The level steps of removing prefixes and affixes from the Kurdish word
The proposed approach guarantees to choose the best path for obtaining the stem. The above graph explains that in level four (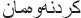 ) is ended with three different suffixes. The suffixes of (
) is ended with three different suffixes. The suffixes of ( ) and (
) and (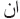 ) are selected as the best suffix to arrive at the stem that is (
) are selected as the best suffix to arrive at the stem that is (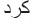 ) while (
) while (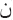 ) is not selected since the length of character of (
) is not selected since the length of character of (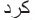 ) is greater than two are and smaller than (
) is greater than two are and smaller than (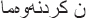 ). However, after removing the suffixes of (
). However, after removing the suffixes of ( ) and (
) and (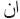 ), still there are suffixes, which have to be removed such as (
), still there are suffixes, which have to be removed such as (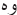 ) and (
) and (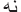 ), there are suffixes, which have to be removed such as (
), there are suffixes, which have to be removed such as (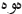 ), (
), (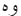 ), (
), ( ), (
), (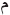 ), and (
), and (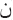 ). Selecting the stem in this approach depending on suffixes, furthermore, high dimensionality of feature space has a greater impact on the performance and efficiency of the text classification algorithm. Thus, usefulness of this approach is to reduce feature space as presented in Table 2.
). Selecting the stem in this approach depending on suffixes, furthermore, high dimensionality of feature space has a greater impact on the performance and efficiency of the text classification algorithm. Thus, usefulness of this approach is to reduce feature space as presented in Table 2.
Table 2. Different illustration of stem
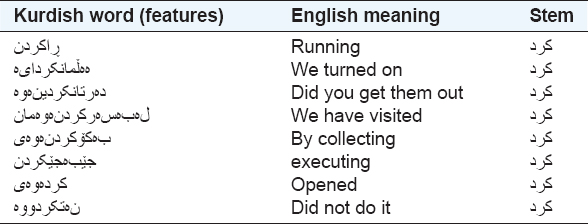
Table 2 illustrates the post implementing of this approach on eight features, only one stem is produced. Accordingly, high dimensionality of features spaces is decreased in the proposed approach.
4. DATA REPRESENTATION
One of the important steps in text classification is to convert unstructured text documents to a form that can be ready to be used by machine learning algorithms. Vector space model (VSM), N-gram, and Bag-of-Words are algorithms that can be implemented for this purpose. VSM is the common method that can be used to represent the text as a vector . Where where wn is the weight term in text documents (Danisman and Adil, 2008). Moreover, vectors have certain weights that are utilized to increase the accuracy of classification when term weighting is executed.
5. CLASSIFICATION
In this research work, KDC-4007 dataset was used to evaluate the proposed approach. SVM and decision tree (C4.5) (Mustafa and Rashid, 2017; Rashid et al., 2017; Saeed et al., 2018) are applied as two common machine learning algorithms for comparing the results. The dataset is partitioned for two inequality portions. The first portions are training that is 70% while the rest is testing that is 30%.
6. RESULT AND DISCUSSION
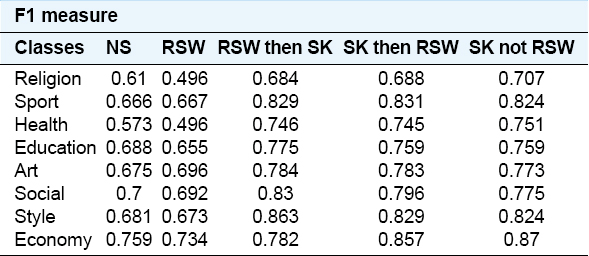
Various experimental tests are used in this paper. Table 3 shows the results of five different experiments and the impact of stemming is exhibited:
Table 3. F1 Performance results for the decision tree (C4.5)
-
The first experiment applies only natural sentences (NS).
-
In the second experiment stop words are removed (RSW).
-
In the third experiment, the RSW and then the stemmer are applied (RSW then SK).
-
In the fourth experiment the stemmer is applied, and then the RSW (SK then RSW).
-
The fifth experiment uses the stemmer but without removing stop words (SK not RSW).
Table 3 exhibits the results of J48 experiments.
Tables 3 and 4 indicate the performance of the proposed stemmer on text classification. The values obtained for F1 measure increased dramatically and the success of this stemmer is depicted when RSW then SK is applied for each class (education, art, social, and style) in decision tree (C4.5) and the classes (health, education, art, social, and economy) in SVM as well while the rest of classes decreased slightly.
However, F1 measure for the stemmer is implemented before and after removing stop words and compared with removing stop word without stemming. According to Tables 3 and 4, the F1 measures for each SK then RSW has different values for each SVM and decision tree (C4.5), for classes of health, education, art, social, and style. In Table 3, classes of religion, sport, and economy have higher F1, while in Table 4, all the class go down gently without style remains in its state. Therefore, it can be said that the success of stemmer before and after removing stop words depended on the type of class in dataset. Figures 3 and 4 represent the performance results of F1 measure on five experiments for each class label via classifiers C4.5 and SVM respectively
Table 4. F1 performance results for the SVM
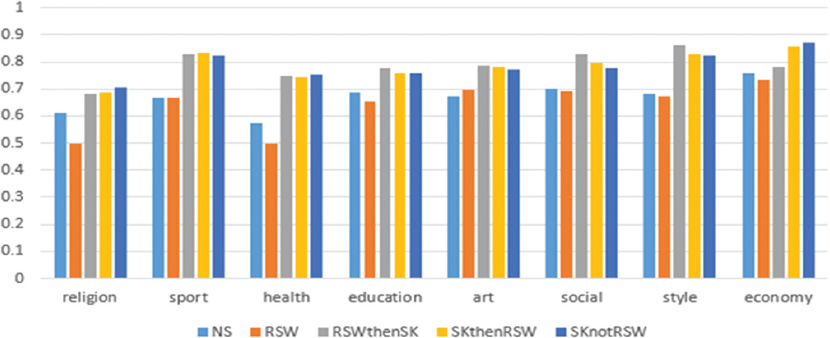
Figure 3. The performance of F1 measure for five experiments using decision tree (C4.5)
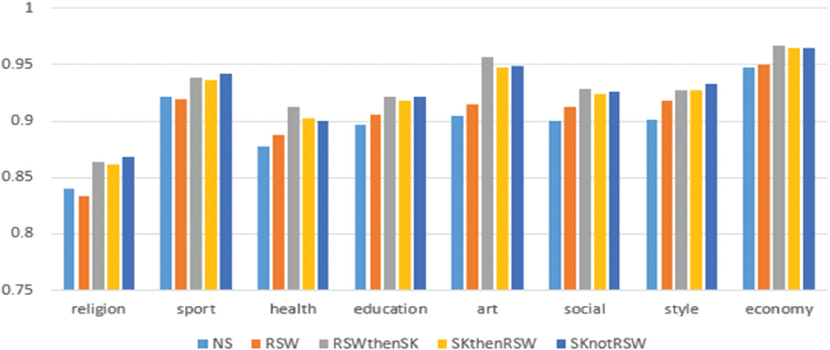
Figure 4. The performance of F1 measure for five experiments using support vector machine
In the decision tree or C4.5 classifier, unlike the experiment SK not RSW, the F1 measure result on the experiments RSW then SK and SK then RSW is decreased for all classes, except for style, which is increased steadily (Figure 3). In the same way, in SVM, the F1 measure result on the mentioned experiments for the classes of religion, sport, education, and style is gradually increased, but classes of health, art, social, and economy is slightly decreased (Figure 4).
7. CONCLUSIONS AND FUTURE WORK
In this research work, a new stemmer approach is examined on KDC-4007 dataset for improving text classification in Kurdish language. The proposed algorithm used tree data structure and Portes stemmer’s techniques. It can be concluded that the F1 measure obtained the best result when the stemmer was implemented and stop words were not removed. Hence, the influence of stop words showed when NS experiment compared with removing stop word experiment.
Another important investigation in this experiment effect this stemmer on stop words.
There are various proposals that can be investigated to improve the efficiency of stemmer in Kurdish text such as mixing new techniques and showed the effects of affix in Kurdish stemmer.